How to find out whether the Machine Learning I did is good or not? (i.e. the quality of our model) Well, it depends. First of all, we have to find performance, which depends on the context in which we want to use model. In some cases, accuracy of model can be the most important thing; in other cases, computation time is a good indicator of performance; and even in other case, interpretability of the model is central. Then, there are 3 types of tasks in Machine Learning: Classification, Regression and Clustering. Each of them has difference performance measures. I’ll introduce these approaches one by one.
Classification
In the Classification system, accuracy and error are the basic performance measures. If Accuracy goes up when Error goes down.
Because of the limit of accuracy, we should calculate the confusion matrix. For now, we focus on binary classifier, there are 2 classes: positive (1) and negative (0)
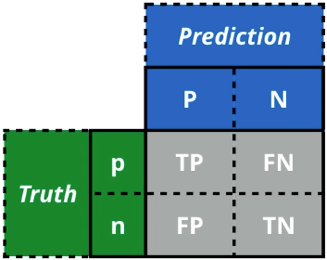
- True Positives – Prediction: P, Truth: P
- True Negatives – Prediction: N, Truth: N
- False Negatives – Prediction: N, Truth: P
- False Positives – Prediction: P, Truth: N
Accuracy = (TP + TN) / (TP + FP + FN + TN)
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)Regression
To compare the performance of regression algorithms, we can use the Root Mean Squared Error (RMSE). This term is calculated by the following formula, which gives us the mean distance between estimates and regression line.
: actual outcome for obs. i
: predicted outcome for obs. i
- N: Number of observations
Clustering
There are different ways to see if Clustering does a good job. Here, we have no label information, so we have to know distance metric between points. More specifically, performance measure for clustering consists of 2 elements: their similarity within each cluster (how the points in the same cluster are like?) and their similarity between clusters (how the points in two different clusters are similar?). The first metric, the similarity within each cluster should be high; and the second metric, similarity between clusters should be low.
There are several techniques to measure these two concepts. For within cluster similarity, there is Within cluster Sum of Squares (WSS) and Diameter. The smaller Within Sum of Squares and the smaller Diameter, the more the points inside the same cluster are similar. For between cluster similarity, we can use Between cluster Sum of Squares (BSS) or the Intercluster distance. The higher they are, the less similar the clusters are.
Moreover, a popular performance index to compare clustering algorithms is Dunn’s index.
Reference
- Engin Akyurt, “black and white dartboard”, www.pexels.com. [Online]. Available: https://www.pexels.com/photo/black-and-white-dartboard-1552617/