These days I cleaned my codes for different reports and analyses, which allows
the scripts to be more brief and to increase running speed. In this blog, I’ll
pay particular emphasis on how to improve pandas dataframe processing with
the following points:
- Take advantage of SQL query
- Apply
maporlambdarather than for loop - Quick tips
Take advantage of SQL query
Here, I only talk about Teradata SQL query.

- Replace python function by
COALESCEin Teradata SQL
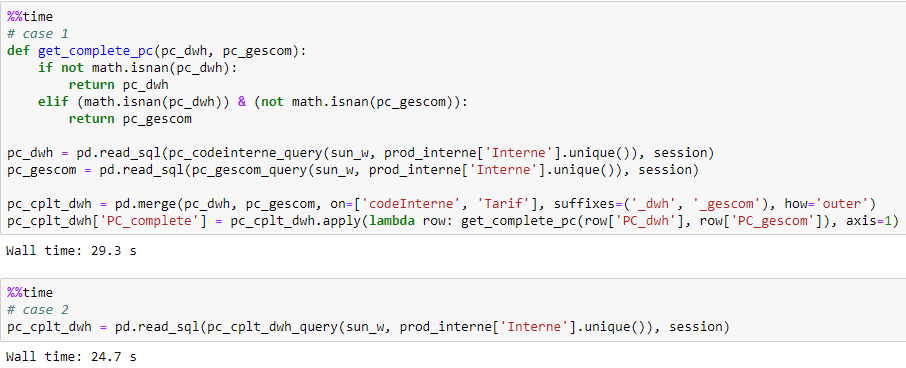
In this example, I need to complete the store’s purchase price according to “pc_dwh” and “pc_gescom”. If “pc_dwh” exists, I’ll take it as the store’s purchase price; if not, I’ll take “pc_gescom”.
At the beginning, I created a function called get_complete_pc() with “pc_dwh”
and “pc_gescom” as input. In fact, this rule can simply be applied by
COALESCE in Teradata SQL.
- Replace
pandas.merge()byJOINin SQL
Moreover, in the example above, I merged dataframes “pc_dwh” and “pc_gescom” to
get complete store’s purchase price. Since I could replace the function with
COALESCE in Teradata SQL, I also replaced pandas.merge() by JOIN in
Teradata SQL, since SQL is good at this kind of operation.
As shown below, the processing speeds up nearly 20%!
Apply map or lambda rather than for loop

In this example, I need to check if the last character of “codeInterne” is “.”. If it is, I’ll just take into account its first 4 characters as “codeInterne”.
At the beginning, I applies a for loop to iterate each row, search if the
last character is “.” for each “codeInterne”. However, this logic can be
implemented by map. As you see above, I created a function called
“update_codeInterne()” with an input “codeInterne”, then map the function to
each “codeInterne”.
As shown below, the processing speeds up more than thousands of times!

Extended by map example, I’d like to share with you the general order of
precedence for performance of various operations:(click herefor more
details)
1) vectorization
2) using a custom cython routine
3) apply
a) reductions that can be performed in cython
b) iteration in python space
4) itertuples
5) iterrows
6) updating an empty frame (e.g. using loc one-row-at-a-time)
Quick tips
- Specifying date columns as
parse_dateswhenpandas.read_csv() - Applying aggregation or join in SQL, since it is good at that.
- Applying comprehensions (list comprehension, dict comprehension and set comprehension) rather than multiple-lines for loop.
Conclusion
In this blog I talked about how to improve pandas dataframe processing with
the SQL query, map or lambda and some other quick tips. Hope it’s useful
for you.
Reference
- “Does pandas iterrows have performance issues?”, stackoverflow.com. [Online]. Available: https://stackoverflow.com/questions/24870953/does-pandas-iterrows-have-performance-issues/24871316#24871316
- Free-Photos, “Bike riding fast moving bike motion”, pixabay.com. [Online]. Available: https://pixabay.com/photos/bike-riding-fast-moving-bike-motion-1149234/