Introduction
Imagine that we need to calculat some KPIs by running Azure Databricks notebook, before the calculation we also need to check our input data to ensure that they satisfy some rules, such as check if clients are in our database, check if there is the overlap between the period of analysis and the period of comparison, or count the sample of each input files (clients, stores, or products), etc. Sometimes, the demand comes from other teams, like marketing or innovation teams, to optimise the working process, creating a data pipeline and communicate on slack should be helpful. Since in my working environment, we use Microsoft Azure, in this blog, I’ll create a data pipeline with Azure Data Factory and talk about the following points:
- What is Microsoft Azure?
- What is Slack?
- How to create a date pipeline with Azure Data Factory and Databricks?
- How to communicate data pipeline’s result on Slack?
What is Microsoft Azure?
Microsoft Azure, commonly referred to as Azure, is a cloud computing service created by Microsoft for building, testing, deploying, and managing applications and services through Microsoft-managed data centers. It provides software as a service (SaaS), platform as a service (PaaS) and infrastructure as a service (IaaS) and supports many different programming languages, tools, and frameworks, including both Microsoft-specific and third-party software and systems. Moreover, Azure Data Factory is a data integration service that allows creation of data-driven workflows in the cloud for orchestrating and automating data movement and data transformation.
Furthermore, Databricks is an enterprise software company founded by the original creators of Apache Spark. Databricks develops a web-based platform for working with Spark, that provides automated cluster management and IPython-style notebooks. In November 2017, the company was announced as a first-party service on Microsoft Azure via the integration Azure Databricks.
What is Slack?
Slack is a proprietary business communication platform developed by American software company Slack Technologies. Slack offers many IRC-style features, including persistent chat rooms (channels) organized by topic, private groups, and direct messaging. For more information, you can find them here.
How to create a date pipeline with Azure Data Factory and Databricks?
Before beginning, you need to have/create a Databricks workspace, prepare the Python notebook that you want to execute using Azure Data Factory. We have 2 main steps for automating the execution of notebook:
- Create a data pipeline in Azure Data Factory
- Create a trigger for running a pipeline
Create a data pipeline in Azure Data Factory
I won’t show more details for the step, since you can find them in this tutorial as the following steps:
- Create a data factory.
- Create a pipeline that uses Databricks Notebook Activity.
- Trigger a pipeline run.
- Monitor the pipeline run.
Create a trigger for running a pipeline
Triggers represent a unit of processing that determines when a pipeline execution needs to be kicked off. Currently, Data Factory supports three types of triggers:
- Schedule trigger: A trigger that invokes a pipeline on a wall-clock schedule.
- Tumbling window trigger: A trigger that operates on a periodic interval, while also retaining state.
- Event-based trigger: A trigger that responds to an event, like a storage event or a custom event.
Same as above, you can find all tutorials with the links.
How to communicate data pipeline’s result on Slack?
Slack provides a range of APIs that provide access to read, write, and update many types of data in Slack. To communicate data pipeline’s result on Slack, we can send messages to a channel or upload files on a channel.
Slack APIs
Send messages to a channel
We can use chat.postMessage for posting a message to a
public channel, private channel, or direct message/IM channel.
A request is an HTTP URL of the following form:
POST https://slack.com/api/chat.postMessage
with certain arguments:
token: (Required) Authentication token bearing required scopes. Tokens should be passed as an HTTP Authorization header or alternatively, as aPOSTparameter.channel: (Required) Channel, private group, or IM channel to send message to. Can be an encoded ID, or a name.
About more information of arguments, you can find them here.
Upload files
We can use files.upload for creating or uploading an existing
file.
A request is an HTTP URL of the following form:
POST https://slack.com/api/files.upload
with certain arguments:
token: (Required) Authentication token bearing required scopes. Tokens should be passed as an HTTP Authorization header or alternatively, as aPOSTparameter.
About more information of arguments, you can find them here.
How to find channel ID on Slack?
To send messages or upload files to a public channel, a multi-person direct message or a direct message to someone, we need to get the channel ID, but where can we find them?
The public channel’s ID
When we open Slack with navigator, we can find it in the URL, with the following format:
https://app.slack.com/client/TD123ABCD/C024BE91L
The last part of the URL(C024BE91L) above starts with “C”, which presents
the public channel’s ID.
The multi-person direct message’s ID
Similar as above, let’s open Slack with navigator, we can find it in the URL, with the following format:
https://app.slack.com/client/TD123ABCD/G012AC86C
The last part of the URL(G012AC86C) above starts with “G”, which presents
the group’s ID.
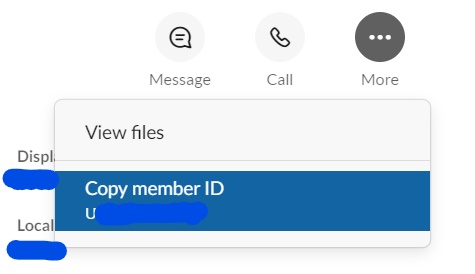
The user’s ID
For a User’s ID, we can find it both on the website or the application. When we check someone’s profile, we can find the ID (starts with “U”) by clicking “More”.
How to realise it via Python?
Send messages to a channel
We can send the messages with requests.post() by specify the token,
the channel ID and message that you want to send.
import requests
requests.post("https://slack.com/api/chat.postMessage", {
"token": "as-123dfghj456-klqwert7y8u9iop",
"channel": "U012AB34C",
"text": "test"
})
I sent a message “test” with Databricks Message Bot on Slack, and received a message as below.

Upload files
We can upload the file with requests.post() by specify the file path, the
token, the channel ID and initial_comment if you want to introduce the file.
import requests
requests.post("https://slack.com/api/files.upload",
params= {
"filename": "/path/of/file",
"token": "as-123dfghj456-klqwert7y8u9iop",
"channels": "U012AB34C",
"initial_comment" : "test file"},
files= {
"file" : ("/path/of/file",
open("/path/of/file", 'rb'),
os.path.splitext(os.path.basename("/path/of/file"))[1][1:])}
)
Conclusion
In this blog, I talked about how to create and automate a data pipeline on Azure Data Factory, how to send messages and upload files on Slack with its APIs. Hope it’s helpful for you!
References
- “Microsoft Azure”, en.wikipedia.org. [Online]. Available: https://en.wikipedia.org/wiki/Microsoft_Azure
- “Databricks”, en.wikipedia.org. [Online]. Available: https://en.wikipedia.org/wiki/Databricks
- “Slack (software)”, en.wikipedia.org. [Online]. Available: https://en.wikipedia.org/wiki/Slack_(software)
- “Run a Databricks notebook with the Databricks Notebook Activity in Azure Data Factory”, docs.microsoft.com. [Online]. Available: https://docs.microsoft.com/en-gb/azure/data-factory/transform-data-using-databricks-notebook
- “Pipeline execution and triggers in Azure Data Factory”, docs.microsoft.com. [Online]. Available: https://docs.microsoft.com/en-gb/azure/data-factory/concepts-pipeline-execution-triggers
- billycm, “pipe rea l’eau metal pipeline”, pixabay.com. [Online]. Available: https://pixabay.com/fr/photos/pipe-red-l-eau-m%C3%A9tal-pipeline-2369719/